Core features in MySQL
Structured database
Basically, data in a structured database has a fixed field, a predefined data length, and defines what kind of data is to be stored such as numbers, dates, time, addresses, currencies, and so on. In short, the structure is already defined before data gets inserted, which gives a clearer idea of what data can reside there. The key advantage of using a structured database is that data being easily stored, queried, and analyzed.
Mainly, the source of structured data is machine-generated, which means information is generated from the machine and without human intervention, whereas unstructured data is human-generated data. Organizations use structured databases for data such as ATM transactions, airline reservations, inventory systems, and so on.
Database storage engines and types
The storage engine is the way to handle SQL operations for different table types. Each storage engine has its own advantages and disadvantages.
InnoDB is the default storage engine when we create a new table in MySQL 8.
Overview of InnoDB
InnoDB tables support ACID-compliant commits, rollback, and crash recovery capabilities to protect user data. It also supports row-level locking, which helps with better concurrency and performance. It stores data in clustered indexes to reduce I/O operations for all SQL select queries based on the primary key. It also supports FOREIGN KEY constraints that allow better data integrity for the database. The maximum size of an InnoDB table can scale up to 64 TB, which should be good enough to serve many real-world use cases.
Overview of MyISAM
MyISAM was the default storage engine for MySQL prior to 5.5 1. MyISAM storage engine tables do not support ACID-compliant as opposed to InnoDB. MyISAM tables support table-level locking only, so MyISAM tables are not transaction-safe; however, they are optimized for compression and speed. It is generally used when you need to have primarily read operations with minimal transaction data. The maximum size of a MyISAM table can grow up to 256 TB, which helps in use cases such as data analytics. MyISAM supports full-text indexing, which can help in complex search operations. Using full-text indexes, we can index data stored in BLOB and TEXT data types.
Overview of memory
A memory storage engine is generally known as a heap storage engine. It is used to access data extremely quickly. This storage engine stores data in the RAM so it wouldn't need I/O operation. As it stores data in the RAM, all data is lost upon server restart. This table is basically used for temporary tables or the lookup table. This engine supports table-level locking, which limits high write concurrency.
Overview of archive
This storage engine is used to store large amounts of historical data without any indexes. Archive tables do not have any storage limitations. The archive storage engine is optimized for high insert operations and also supports row-level locking. These tables store data in a compressed and small format. The archive engine does not support DELETE or UPDATE operations; it only allows INSERT, REPLACE, and SELECT operations.
Overview of BLACKHOLE as a storage engine
This storage engine accepts data but does not store it. It discards data after every INSERT instead of storing it.
This engine is useful for replication with large number of servers. A BLACKHOLE storage engine acts as a filter server between the master and slave server, which do not store any data, but only apply replicate-do-* and replicate-ignore-* rules and write a binlogs. These binlogs are used to perform replication in slave servers.
Overview of CSV
The comma separated values (CSV) engine stores data in the .csv file type using the comma-separated values format. This engine extracts data from the database and copies it to .csv out of the database. This storage engine is used for the exchange of data between software or applications. A CSV table does not support indexing and partitioning.
Overview of merge
This storage engine is also known as an MRG_MyISAM storage engine. This storage engine merges a MyISAM table and creates it to be referred to a single view. For a merge table, all columns are listed in the same order. These tables are good for data warehousing environments.
Overview of federated
This storage engine allows you to create a single database on a multiple physical server. It opens a client connection to another server and executes queries against a table there, retrieving and sending rows as needed. Although it seemed to enable a lot of flexibility and neat tricks, it has proven to be a source of many problems and is disabled by default.
Overview of the NDB cluster
NDB cluster (also known as NDB) is an in-memory storage engine offering high availability and data persistence features.
The NDB cluster storage engine can be configured with a range of failover and load balancing options, but it is easiest to start with the storage engine at the cluster level. NDB cluster uses the NDB storage engine that contains a complete set of data, which is dependent only on other datasets available within the cluster.
The cluster portion of the NDB cluster is configured independently of the MySQL servers. In an NDB cluster, each part of the cluster is considered to be a node.
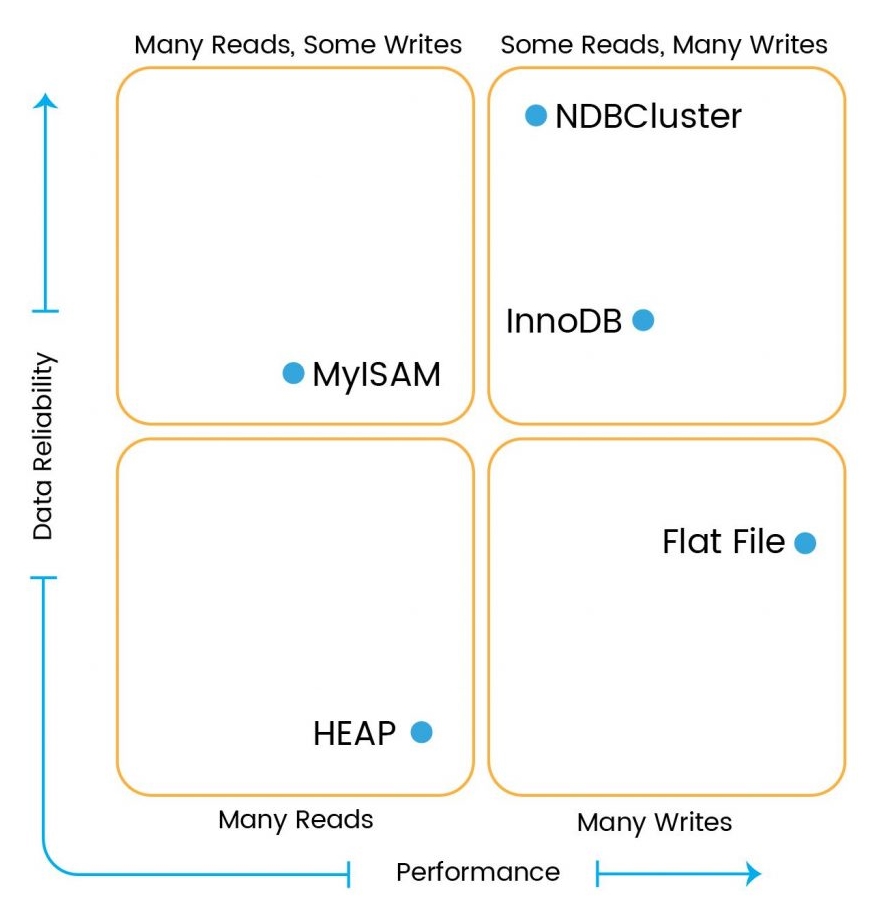
Each storage engine has its own advantage and usability, as follows:
- Search Engine: NDBCluster
- Transactional data:
InnoDB - Session data:
MyISAMor NDBCluster - Localized calculations: Memory
- Dictionary:
MyISAM
The following diagram will help you understand which store engine you need to use for your requirement: